The SELECT CASE Construct is similar to an IF construct. It is a useful control construct if one of several paths through an algorithm must be chosen based on the value of a particular expression.
SELECT CASE (i)
CASE (3,5,7)
PRINT*,"i is prime"
CASE (10:)
PRINT*,"i is > 10"
CASE DEFAULT
PRINT*, "i is not prime and is < 10"
END SELECT
The first branch is executed if i is equal to 3, 5 or 7, the second if i is greater than or equal to 10 and the third branch if neither of the previous has already been executed.
A slightly more complex example with the corresponding IF structure given as a comment,
SELECT CASE (num)
CASE (6,9,99,66)
! IF(num==6.OR. .. .OR.num==66) THEN
PRINT*, "Woof woof"
CASE (10:65,67:98)
! ELSEIF((num.GE.10.AND.num.LE.65) .OR. ...
PRINT*, "Bow wow"
CASE (100:)
! ELSEIF (num.GE.100) THEN
PRINT*, "Bark"
CASE DEFAULT
! ELSE
PRINT*, "Meow"
END SELECT
! ENDIF
Important points are,
(An IF .. ENDIF construct could be used but a SELECT CASE is neater and more efficient.)
SELECT CASE is more efficient than ELSEIF because there is only one expression that controls the branching. The expression needs to be evaluated once and then control transferred to whichever branch corresponds to the expressions value. An IF .. ELSEIF ... has the potential to have a different expression to evaluate at each branch point making it less efficient.
Consider the SELECT CASE construct,
SELECT CASE (I)
CASE(1); Print*, "I==1"
CASE(2:9); Print*, "I>=2 and I<=9"
CASE(10); Print*, "I>=10"
CASE DEFAULT; Print*, "I<=0"
END SELECT CASE
this maps onto the following control flow structure,
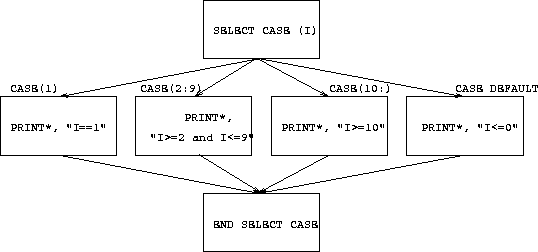
Figure 5: Visualisation of a SELECT CASE Construct
The syntax is as follows,
[ < name >:] SELECT CASE < case-expr >[ CASE < case-selector > [ < name > ]
< exec-stmts > ] ...
[ CASE DEFAULT [ < name > ]
< exec-stmts > ]
END SELECT [ < name > ]
Note,
CASE constructs may be named -- if the header is named then so must be the END SELECT statement. If any of the CASE branches are named then so must be the SELECT statement and the END statement
A more complex example is given below, this also demonstrates how SELECT CASE constructs may be named.
...
outa: SELECT CASE (n)
CASE (:-1) outa
M = -1
CASE (1:) outa
DO i = 1, n
inna: SELECT CASE (line(i:i))
CASE ('@','&','*','$')
PRINT*, "At EOL"
CASE ('a':'z','A':'Z')
PRINT*, "Alphabetic"
CASE DEFAULT
PRINT*, "CHAR OK"
END SELECT inna
END DO
CASE DEFAULT outa
PRINT*, "N is zero"
END SELECT outa
Analysis:
Return to corresponding overview page 